
The Totmundo Project
The Project
1. Introducción.
La desaparición de la liturgia hispánica (también conocida como visigótica) a finales del siglo XI previno que las melodías de sus cantos, anotados con neumas que no codifican la altura definida de los sonidos, fueran transcritos con sistemas de notación posteriores y más avanzados, basados ya en notas musicales [1,2]. Este hecho ha levantado hasta el momento una barrera infranqueable para los investigadores que han abordado el problema de la restitución del sonido escondido tras los neumas hispánicos [1]. La existencia de todo un corpus de cantos, con melodías que muestran cualitativamente un perfil muy adornado, pero cuyo sonido ha permanecido silenciado durante un milenio, sigue suponiendo un desafío de primer orden a la investigación musicológica internacional.
Para abordar el estudio de los neumas hispánicos yendo más allá de lo que permite la metodología musicológica tradicional, hemos desarrollado el Proyecto Totmundo, basado en el reconocimiento óptico y el análisis informático-estadístico de estos neumas. El proyecto Totmundo toma su nombre del abad encargado de la copia (en el siglo X según se estima) del manuscrito que constituye la principal fuente del canto hispánico: el Antifonario Mozárabe de la Catedral de León (León, Archivo Catedralicio núm. 8). Este manuscrito -al que nos referiremos a partir de ahora simplemente como el Antifonario- contiene el corpus de cantos de las celebraciones de la liturgia hispánica o mozárabe, en vigor en los reinos cristianos peninsulares hasta su sustitución por los cantos del rito romano hacia el final del siglo XI. La Figura 1 muestra un fragmento de una de las 556 páginas de contenido musical del Antifonario, un contenido que, de manera global, se estima incluye varios cientos de miles de signos musicales, los denominados neumas hispánicos. Estos neumas, de manera semejante a las notaciones musicales de otras tradiciones litúrgicas de la Europa de la época, sólo indicaban la altura de los sonidos de un modo relativo, sin especificar la cantidad de los intervalos.

La propuesta multidisciplinar del Proyecto Totmundo se basa, en primer lugar, en el desarrollo de un sistema de reconocimiento óptico de caracteres musicales manuscritos (OCR, por optical character recognition) para realizar una catalogación semisupervisada de los cientos de miles de neumas contenidos en el Antifonario. Lograr una OCR eficiente a partir de fuentes manuscritas antiguas es un problema técnico de primer orden que requerirá el uso de recursos computacionales muy intensos (computación paralela).
Sin embargo, la OCR será el fundamento de la Fase Analítica ulterior, en la que, usando herramientas adaptadas de la genómica y la bioinformática, se abordarán asuntos como la búsqueda de correlaciones significativas entre los distintos tipos de signos musicales, y la identificación de fórmulas melódicas estereotipadas o intercambiables entre los distintos cantos. En última instancia, nuestro objetivo no es otro que arrojar luz sobre la dinámica evolutiva del canto hispánico y sobre el contenido melódico de un corpus musical que sigue aún esperando su restitución sonora.
2. Necesidad y relevancia de la OCR.
Límites de la musicología tradicionalA partir de la aproximación musicológica tradicional (esencialmente centrada en el estudio de la semántica de los signos musicales individuales) tenemos ya una clara idea del significado melódico cualitativo de muchos de los neumas hispánicos [3-11]. Y por cualitativo entendemos el hecho de que sabemos, por ejemplo, que los neumas tipo pes codifican dos sonidos en sucesión ascendente, pero sin que se especifique el intervalo melódico concreto formado por estos dos sonidos. Tampoco sabemos qué intervalo ha de cantarse al pasar de un neuma al siguiente. Es precisamente en la carencia de cuantificaciones interválicas típicas de esta notación donde radica la dificultad (e incluso la aparente imposibilidad) de lograr una restitución sonora del corpus de cantos hispánicos [12].
Enfoque a media escala.Más allá del ámbito de estudio local centrado en el neuma, algunos autores han sido capaces de reconocer que ciertas sucesiones de neumas en los versículos de los cantos responsoriales constituyen fórmulas estereotipadas. Así, la clave que autores como Ismael Fernández de la Cuesta o Don Michael Randel dan para avanzar significativamente en el estudio de las melodías hispánicas estriba precisamente en la identificación de estereotipos melódicos (en la forma de sucesiones de neumas típicas), así como de células melódicas intercambiables (las técnicamente denominadas centones) a través de la comparación de los cantos entre sí [12-15]. Dicho de otro modo, es probable que la transición desde el estudio de los neumas de un modo individualizado a un nuevo enfoque a media escala, considerando ahora fragmentos significativos de cantos -representados por sucesiones de neumas de mayor o menor longitud-, es probable, decimos, que esto permita dar un salto cualitativo en el terreno de la descodificación sonora de las melodías hispánicas.
La media escala en la práctica.Dicho esto, ahora vendría el problema técnico de llevar esta propuesta a la práctica. Nótese lo siguiente: sólo considerando el caso del Antifonario, ¿cómo se puede realizar una comparación entre cadenas de 10 a 100 neumas en un conjunto de cientos de miles de ellos? Evidentemente, esta es una tarea que los ordenadores son capaces de hacer con mucha más eficacia y, sobre todo, con mucha más rapidez que cualquier experto humano que aborde el asunto mediante la inspección visual del bosque de signos contenidos en el Antifonario.
Sucede que la búsqueda de patrones en sucesiones de caracteres en el seno de bases de datos de gran tamaño es ya un hecho cotidiano en el mundo de la genómica y la bioinformática. En la Fase II del Proyecto Totmundo nuestra intención será la de trasladar estas técnicas desde el campo original para el que fueron desarrolladas al terreno musicológico del estudio de los cantos hispánicos (véase la sección 3.3). Gracias a ellas estaremos en condiciones de abordar de un modo global la cuestión de la existencia de secuencias melódicas prototípicas en este corpus de cantos. No obstante, existe un escollo esencial que es necesario salvar con carácter previo a cualquier intento de análisis del canto hispánico por la vía informático-estadística: hacer que una máquina sea capaz de “leer” neumas.
Necesidad de la OCR.El cerebro humano, gracias a su óptima capacidad para el reconocimiento de patrones, puede identificar directamente una secuencia de neumas en un pergamino o en una imagen digital del mismo. Esto no es así para las máquinas. Los análisis informáticos han de partir de un fichero de texto que contenga las sucesiones de neumas codificadas en la forma de sucesiones de caracteres; y para obtener tal fichero es necesario realizar un proceso de OCR sobre los neumas del Antifonario. Como los neumas son manuscritos, el proceso de OCR es mucho más complejo que el que se utiliza en los programas comerciales, dedicados en su práctica totalidad al reconocimiento de tipos de imprenta [16]. Además, a esto hay que añadir el hecho de que tratamos con un manuscrito antiguo que, con sus zonas de bajo contraste, manchas y calados, dificulta la identificación de los neumas frente al fondo del pergamino [17,18]. Por ello, la Fase I del Proyecto Totmundo está dedicada en su integridad al desarrollo de una OCR específica de los cientos de miles de neumas del Antifonario. El documento base para realizar la OCR es la Versión Digital del Antifonario llevada a cabo por el Ministerio de Cultura de España en el año 2011.
Finalmente, una vez que dispongamos de una versión de este manuscrito que sea "legible" para los ordenadores, podremos pasar al uso de toda la batería de herramientas informático-estadísticas que permitan arrojar luz sobre la cuestión musicológica y cultural de primer orden que en última instancia nos ocupa: la restitución, aunque sea de manera parcial, del sonido de este corpus de melodías milenarias.
3. Fases del Proyecto Totmundo.
El Proyecto Totmundo consta de dos fases:
- Fase I: Reconocimiento óptico de los neumas (OCR). Esta fase consta a su vez de tres etapas:
- Binarización y extracción de objetos conexos.
- Elaboración del conjunto de entrenamiento de la OCR.
- OCR propiamente dicha.
- Fase II: Análisis estadistico inspirado por técnicas bioinformáticas.
Fase I: Reconocimiento óptico de caracteres musicales manuscritos.
La etapa preliminar de la OCR consistió en la binarización y segmentación de las imágenes escaneadas de los folios del Antifonario. Por binarización entendemos la conversión de una imagen a color (o en escala de grises, Figura 2.A) a otra imagen en blanco y negro absolutos (Figura 2.B). La binarización de imágenes de documentos antiguos no es una tarea sencilla por los problemas de degradación mencionados, y descansa en procesos multietapa que incluyen, entre otros componentes, la definición de umbrales locales en las distintas zonas de una imagen, y la estimación progresiva de aquello que se va considerar fondo y texto [17,18].
Tras el proceso de binarización se procedió a realizar el de segmentación de la imagen binaria resultante. En el contexto de la disciplina de análisis de imágenes se entiende por segmentación la localización de objetos dentro de una imagen. En nuestro caso la segmentación consistió en la identificación de todos los objetos conexos de la imagen binaria, entendiendo aquí por objeto conexo el neuma o la parte de neuma incluido en un solo trazo de escritura -un neuma puede constar así de varios de estos objetos (véase la Figura 2.C y su pie de imagen).

La segunda subetapa de la OCR es la de elaboración del conjunto de entrenamiento en la cual al algoritmo de reconocimiento se le enseña a identificar cada tipo de signo. Para ello había que seleccionar un subconjunto de los signos musicales contenidos en el Antifonario y clasificarlos manualmente en la categoría correcta. A este subconjunto se le denomina conjunto de entrenamiento (CE). En nuestro caso, el CE fue contruido definiendo una región de muestreo entre dos líneas de texto en la zona central de cada página del Antifonario con contenido musical (556 páginas, luego 556 zonas de muestreo). Las imágenes de la Figura 2 corresponden a la zona de muestreo del folio 72r.
El conjunto de todos los simbolos contenidos en todas las zonas de muestreo constituyeron un CE de unos 15000 objetos conexos. Nótese que aún involucrando a sólo una pequeña fracción de los cientos de miles de signos del Antifonario, estos 15000 objetos contituían aún un número muy grande como para abordar su clasificación manual de uno en uno. Así que para realizar esta tarea de un modo más eficiente (y menos tedioso) desarrollamos una aplicación de catalogación que partía de la agrupación previa de los objetos en subconjuntos de similitud, de manera que se podía llevar a cabo el etiquetado de muchos signos de manera simultánea (Figura 3).
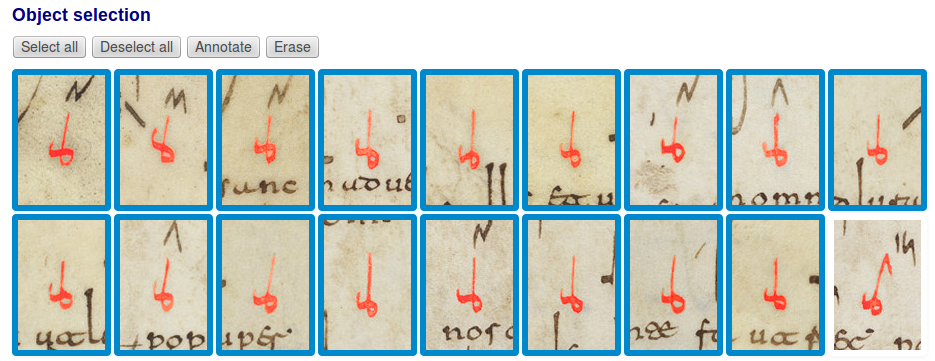
El Proyecto Totmundo ha concluido recientemente esta fase de entrenamiento de la OCR. Queremos ofrecer a la comunidad de investigadores y al público en general el resultado de la misma. A los neumas catalogados dentro de una misma categoría se puede acceder de dos maneras:
- A través de la Tabla con la estadística de la clasificación por categorías.
- Accediendo a la Visualización de Categorías, donde se puede seleccionar la categoría deseada a partir de un menú de signos (una versión en modo de sólo lectura de la aplicación de catalogación de la Figura 3).
La tercera y última parte de la OCR es la etapa de reconocimiento propiamente dicho. Una vez entrenado el ordenador mediante el etiquetado del CE, se ha de proceder al reconocimiento o clasificación del resto de signos contenidos en el Antifonario mediante alguno de los algoritmos que se suelen usar en la disciplina computacional de reconocimiento de patrones (pattern recognition). A partir de aquí ya estaríamos en condiciones de proceder con el desarrollo de la Fase II del Proyecto Totmundo, la fase analítica, en la que entrarían en juego la batería de herramientas informático-estadísticas que, importadas de la genómica, se usarán para encontrar correlaciones significativas entre los neumas.
Fase II: Análisis estadistico inspirado por técnicas bioinformáticas.
Como dijimos más arriba, uno de los objetivos musicológicos principales del Proyecto Tomundo es la identificación de cadenas de neumas que tengan especial relevancia por su recurrencia a lo largo del Antifonario. Para ello, en la Fase II del Proyecto Totmundo adaptaremos herramientas de las disciplinas de genómica y bioinformática, en las cuales la búsqueda de caracteres en el seno de bases de datos de gran tamaño es un hecho cotidiano.
El modelo bioinformático.Para ilustrar lo anterior, veamos ahora un ejemplo del tipo de análisis que pretendemos transferir al ámbito del estudio de los cantos hispánicos. La Figura 4.A muestra la secuencia de 5 pequeños fragmentos de proteínas similares. La sucesión de aminoácidos en cada uno de estos fragmentos se ha codificado en una línea de texto en forma de sucesiones de letras pertenecientes al alfabeto de símbolos que se utiliza para representar cada uno de los 20 tipos de aminoácidos de los que están compuestas todas la proteínas. En la Figura 4.B estas mismas secuencias se muestran alineadas. Como se ve, al realizar el alineamiento (con alguno de los programas bioinformáticos especializados como MUSCLE [19]) quedan en evidencia fenómenos típicos de la evolución de las proteínas como la sustitución de un aminoácido por otro (mutación) o la pérdida/ganancia de aminoácidos, lo cual, a su vez, puede involucrar una sola posición en el alineamiento o un segmento con varias.
A
#1 KATLKDIAEYFGVSISTVSRALSGKPGVSSEL...
#2 RPTINDVAKLAGVSISTVSRYLKDPSQSEKL...
#3 YVTIRDIAEKAINTVSRALNNKPDISEET...
#4 MASIKDVAKLAGVSIATVINGYNNVSEET...
#5 MPTIEAGVSIATVSRVINGSGYVSEKT...
B
#1 KATLKDIAEYFGVSISTVSRALSGKPGVSS-EL...
#2 RPTINDVAKLAGVSISTVSRYLKDPSQ-S-EKL...
#3 YVTIRDIAEKA---INTVSRALNNKPDIS-EET...
#4 MASIKDVAKLAGVSIATV---INGYNNVS-EET...
#5 MPTIE-----AGVSIATVSRVINGSGYVS-EKT...
Pues bien, si en lugar de 5 proteínas, tuviésemos 5 fragmentos musicales similares, esto es, 5 sucesiones de neumas hasta cierto punto semejantes (melodías homólogas), el alineamiento de las mismas permitiría identificar procesos como:
- Eventos de mutación en la melodía definidos por la sustitución de un neuma por otro. Por supuesto, una pregunta de interés musicológico inmediato sería comprobar si en tales mutaciones dominan los intercambios entre neumas que hasta ahora creemos equivalentes (hay por ejemplo al menos seis variantes distintas para el neuma tipo porrectus, que consta de tres notas siendo la central más grave que las otras dos, Figura 5).
- Eventos de ganancia o pérdidas de sonidos puntuales o de células melódicas de mayor extensión.

Por supuesto, antes de poder realizar tales alineamientos hay que encontrar las regiones de similitud melódica, comparando todas las melodías entre sí y definiendo familias de melodías. Para ello, existen otros programas bioinformáticos (como BLAST[20] o USEARCH [21]) especializados en la búsqueda de tales regiones homólogas en bancos de datos con miles de proteínas y cuyos algoritmos habrá que trasladar al terreno de nuestro interés.
Por otro lado, la búsqueda de cadenas recurrentes de neumas es equivalente a la búsqueda de motivos de 10 a 30 nucleótidos en un genoma, definidos como secuencias de nucleótidos que aparecen con mucha más frecuencia de lo que se esperaría si no hubiese correlación entre los mismos. Existe en genómica toda una batería de herramientas desarrolladas para la búsqueda eficiente de tales motivos (como el Gibbs Motif Sampler [22]) que puede ser adaptadas para encontrar “palabras” de neumas, es decir, asociaciones significativas de signos musicales y patrones recurrentes. Finalmente, a partir del uso de árboles filogenéticos (usando programas como PhyML [23]) esperamos obtener información sobre la propia dinámica evolutiva del canto hispánico.
Perspectivas de aplicabilidad musicológica.El resultado de la OCR automática será un documento de texto (que denominaremos Antifonario-OCR) con cadenas de caracteres representando sucesiones de neumas en una melodía con una eficiencia estimada en el reconocimiento del 90%, o lo que es lo mismo, con una tasa de error en torno al 10%. Con la búsqueda, sobre este documento, de familias de melodías o de fragmentos significativos de las mismas, y en función de su tamaño y distribución a lo largo de todo el Antifonario, estaríamos abordando de un modo global la cuestión de la existencia de secuencias prototípicas en el corpus melódico de los cantos hispánicos.
Y como sucede en genómica, esperamos que buena parte de los resultados analíticos sean robustos ante tasas de errores de este orden debido a que la ingente cantidad de datos que se manejará será probablemente capaz de compensar tales errores. De hecho, bastantes de las cuestiones musicológicas que se pretenden abordar a partir del Antifonario-OCR serán compatibles con tasas de errores bastante mayores que un 10%. Por ejemplo, la identificación de fórmulas melódicas arquetípicas reconocibles como cadenas o ¨palabras¨ de signos fuertemente correlacionados no se verá significativamente obstaculizada por la existencia de unos cuantos signos mal etiquetados en ellas. Esto es así porque al alinear los signos de tales palabras, la ausencia de un signo o su identificación errónea quedarán recogidos como huecos en el alineamiento o como mutaciones puntuales (por emplear la nomenclatura genómica). Es labor del analista comprobar si tales huecos y mutaciones corresponden a variantes reales de una misma fórmula melódica o si son debidas a errores de la OCR.
Un caso extremo de pregunta musicológica compatible con una alta tasa de error, por circunscribirse a un ámbito local, es el estudio del contexto en el que aparece un tipo de neuma dado a lo largo del todo el documento. Así, para responder por ejemplo a la pregunta de qué neumas suelen anteceder o suceder a un pes quassus (Figura 3), bastará con encontrar múltiples ejemplos de tal neuma y ver qué sucede alrededor. Por supuesto, la posibilidad de buscar muchos ejemplos de un mismo signo a lo largo de un bosque de varios cientos de miles de ellos a lo largo de las 556 páginas de contenido musical del Antifonario es ya de interés para cualquier investigador del campo. Por otro lado, fenómenos a gran escala que involucren segmentos significativos de una melodía demandarán preferiblemente bajas tasas de error. Por supuesto, la fase analítica se beneficiará de las sucesivos refinamientos de la OCR provenientes de su paulatina revisión manual posterior.